深入理解 Go map:赋值和扩容迁移
概要
在 上一章节 中,数据结构小节里讲解了大量基础字段,可能你会疑惑需要 #&(!……#(!¥! 来干嘛?接下来我们一起简单了解一下基础概念。再开始研讨今天文章的重点内容。我相信这样你能更好的读懂这篇文章
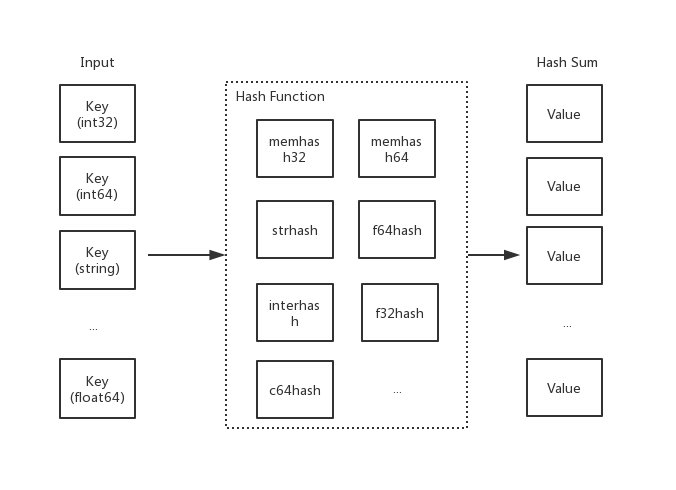
哈希函数
哈希函数,又称散列算法、散列函数。主要作用是通过特定算法将数据根据一定规则组合重新生成得到一个散列值
而在哈希表中,其生成的散列值常用于寻找其键映射到哪一个桶上。而一个好的哈希函数,应当尽量少的出现哈希冲突,以此保证操作哈希表的时间复杂度(但是哈希冲突在目前来讲,是无法避免的。我们需要 “解决” 它)
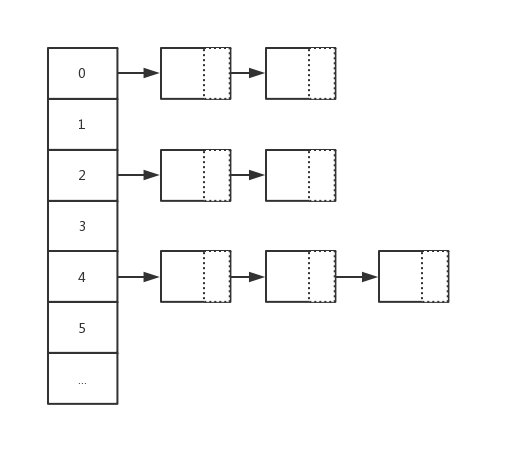
链地址法
在哈希操作中,相当核心的一个处理动作就是 “哈希冲突” 的解决。而在 Go map 中采用的就是 “链地址法 “ 去解决哈希冲突,又称 “拉链法”。其主要做法是数组 + 链表的数据结构,其溢出节点的存储内存都是动态申请的,因此相对更灵活。而每一个元素都是一个链表。如下图:
桶/溢出桶
type hmap struct {...buckets unsafe.Pointer...extra *mapextra}type mapextra struct {overflow *[]*bmapoldoverflow *[]*bmapnextOverflow *bmap}
在上章节中,我们介绍了 Go map 中的桶和溢出桶的概念,在其桶中只能存储 8 个键值对元素。当超过 8 个时,将会使用溢出桶进行存储或进行扩容
你可能会有疑问,hint 大于 8 又会怎么样?答案很明显,性能问题,其时间复杂度改变(也就是执行效率出现问题)
前言
概要复习的差不多后,接下来我们将一同研讨 Go map 的另外三个核心行为:赋值、扩容、迁移。正式开始我们的研讨之旅吧 :)
赋值
m := make(map[int32]string)m[0] = "EDDYCJY"
函数原型
在 map 的赋值动作中,依旧是针对 32/64 位、string、pointer 类型有不同的转换处理,总的函数原型如下:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerfunc mapaccess1_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointerfunc mapaccess2_fast32(t *maptype, h *hmap, key uint32) (unsafe.Pointer, bool)func mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointerfunc mapassign_fast32ptr(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerfunc mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointerfunc mapaccess2_fast64(t *maptype, h *hmap, key uint64) (unsafe.Pointer, bool)func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointerfunc mapassign_fast64ptr(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerfunc mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointerfunc mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool)func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer...
接下来我们将分成几个部分去看看底层在赋值的时候,都做了些什么处理?
源码
第一阶段:校验和初始化
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {if h == nil {panic(plainError("assignment to entry in nil map"))}...if h.flags&hashWriting != 0 {throw("concurrent map writes")}alg := t.key.alghash := alg.hash(key, uintptr(h.hash0))h.flags |= hashWritingif h.buckets == nil {h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)}...}
- 判断 hmap 是否已经初始化(是否为 nil)
- 判断是否并发读写 map,若是则抛出异常
- 根据 key 的不同类型调用不同的 hash 方法计算得出 hash 值
- 设置 flags 标志位,表示有一个 goroutine 正在写入数据。因为
alg.hash有可能出现panic导致异常 - 判断 buckets 是否为 nil,若是则调用
newobject根据当前 bucket 大小进行分配(例如:上章节提到的makemap_small方法,就在初始化时没有初始 buckets,那么它在第一次赋值时就会对 buckets 分配)
第二阶段:寻找可插入位和更新既有值
...again:bucket := hash & bucketMask(h.B)if h.growing() {growWork(t, h, bucket)}b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))top := tophash(hash)var inserti *uint8var insertk unsafe.Pointervar val unsafe.Pointerfor {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if b.tophash[i] == empty && inserti == nil {inserti = &b.tophash[i]insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))}continue}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.indirectkey {k = *((*unsafe.Pointer)(k))}if !alg.equal(key, k) {continue}// already have a mapping for key. Update it.if t.needkeyupdate {typedmemmove(t.key, k, key)}val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))goto done}ovf := b.overflow(t)if ovf == nil {break}b = ovf}if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again // Growing the table invalidates everything, so try again}...
- 根据低八位计算得到 bucket 的内存地址,并判断是否正在扩容,若正在扩容中则先迁移再接着处理
- 计算并得到 bucket 的 bmap 指针地址,计算 key hash 高八位用于查找 Key
- 迭代 buckets 中的每一个 bucket(共 8 个),对比
bucket.tophash与 top(高八位)是否一致 - 若不一致,判断是否为空槽。若是空槽(有两种情况,第一种是没有插入过。第二种是插入后被删除),则把该位置标识为可插入 tophash 位置。注意,这里就是第一个可以插入数据的地方
- 若 key 与当前 k 不匹配则跳过。但若是匹配(也就是原本已经存在),则进行更新。最后跳出并返回 value 的内存地址
- 判断是否迭代完毕,若是则结束迭代 buckets 并更新当前桶位置
- 若满足三个条件:触发最大
LoadFactor、存在过多溢出桶overflow buckets、没有正在进行扩容。就会进行扩容动作(以确保后续的动作)
总的来讲,这一块逻辑做了两件大事,第一是寻找空位,将位置其记录在案,用于后续的插入动作。第二是判断 Key 是否已经存在哈希表中,存在则进行更新。而若是第二种场景,更新完毕后就会进行收尾动作,第一种将继续执行下述的代码
第三阶段:申请新的插入位和插入新值
...if inserti == nil {newb := h.newoverflow(t, b)inserti = &newb.tophash[0]insertk = add(unsafe.Pointer(newb), dataOffset)val = add(insertk, bucketCnt*uintptr(t.keysize))}if t.indirectkey {kmem := newobject(t.key)*(*unsafe.Pointer)(insertk) = kmeminsertk = kmem}if t.indirectvalue {vmem := newobject(t.elem)*(*unsafe.Pointer)(val) = vmem}typedmemmove(t.key, insertk, key)*inserti = toph.count++done:...return val
经过前面迭代寻找动作,若没有找到可插入的位置,意味着当前的所有桶都满了,将重新分配一个新溢出桶用于插入动作。最后再在上一步申请的新插入位置,存储键值对,返回该值的内存地址
第四阶段:写入
但是这里又疑惑了?最后为什么是返回内存地址。这是因为隐藏的最后一步写入动作(将值拷贝到指定内存区域)是通过底层汇编配合来完成的,在 runtime 中只完成了绝大部分的动作
func main() {m := make(map[int32]int32)m[0] = 6666666}
对应的汇编部分:
...0x0099 00153 (test.go:6) CALL runtime.mapassign_fast32(SB)0x009e 00158 (test.go:6) PCDATA $2, $20x009e 00158 (test.go:6) MOVQ 24(SP), AX0x00a3 00163 (test.go:6) PCDATA $2, $00x00a3 00163 (test.go:6) MOVL $6666666, (AX)
这里分为了几个部位,主要是调用 mapassign 函数和拿到值存放的内存地址,再将 6666666 这个值存放进该内存地址中。另外我们看到 PCDATA 指令,主要是包含一些垃圾回收的信息,由编译器产生
小结
通过前面几个阶段的分析,我们可梳理出一些要点。例如:
- 不同类型对应哈希函数不一样
- 高八位用于定位 bucket
- 低八位用于定位 key,快速试错后再进行完整对比
- buckets/overflow buckets 遍历
- 可插入位的处理
- 最终写入动作与底层汇编的交互
扩容
在所有动作中,扩容规则是大家较关注的点,也是赋值里非常重要的一环。因此咱们将这节拉出来,对这块细节进行研讨
什么时候扩容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}
在特定条件的情况下且当前没有正在进行扩容动作(以判断 hmap.oldbuckets != nil 为基准)。哈希表在赋值、删除的动作下会触发扩容行为,条件如下:
- 触发
load factor的最大值,负载因子已达到当前界限 - 溢出桶
overflow buckets过多
什么时候受影响
那么什么情况下会对这两个 “值” 有影响呢?如下:
- 负载因子
load factor,用途是评估哈希表当前的时间复杂度,其与哈希表当前包含的键值对数、桶数量等相关。如果负载因子越大,则说明空间使用率越高,但产生哈希冲突的可能性更高。而负载因子越小,说明空间使用率低,产生哈希冲突的可能性更低 - 溢出桶
overflow buckets的判定与 buckets 总数和 overflow buckets 总数相关联
因子关系
| loadFactor | %overflow | bytes/entry | hitprobe | missprobe |
|---|---|---|---|---|
| 4.00 | 2.13 | 20.77 | 3.00 | 4.00 |
| 4.50 | 4.05 | 17.30 | 3.25 | 4.50 |
| 5.00 | 6.85 | 14.77 | 3.50 | 5.00 |
| 5.50 | 10.55 | 12.94 | 3.75 | 5.50 |
| 6.00 | 15.27 | 11.67 | 4.00 | 6.00 |
| 6.50 | 20.90 | 10.79 | 4.25 | 6.50 |
| 7.00 | 27.14 | 10.15 | 4.50 | 7.00 |
- loadFactor:负载因子
- %overflow:溢出率,具有溢出桶
overflow buckets的桶的百分比 - bytes/entry:每个键值对所的字节数开销
- hitprobe:查找存在的 key 时,平均需要检索的条目数量
- missprobe:查找不存在的 key 时,平均需要检索的条目数量
这一组数据能够体现出不同的负载因子会给哈希表的动作带来怎么样的影响。而在上一章节我们有提到默认的负载因子是 6.5 (loadFactorNum/loadFactorDen),可以看出来是经过测试后取出的一个比较合理的因子。能够较好的影响哈希表的扩容动作的时机
源码剖析
func hashGrow(t *maptype, h *hmap) {bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)...h.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}// the actual copying of the hash table data is done incrementally// by growWork() and evacuate().}
第一阶段:确定扩容容量规则
在上小节有讲到扩容的依据有两种,在 hashGrow 开头就进行了划分。如下:
if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}
若不是负载因子 load factor 超过当前界限,也就是属于溢出桶 overflow buckets 过多的情况。因此本次扩容规则将是 sameSizeGrow,即是不改变大小的扩容动作。那要是前者的情况呢?
bigger := uint8(1)...newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
结合代码分析可得出,若是负载因子 load factor 达到当前界限,将会动态扩容当前大小的两倍作为其新容量大小
第二阶段:初始化、交换新旧 桶/溢出桶
主要是针对扩容的相关数据前置处理,涉及 buckets/oldbuckets、overflow/oldoverflow 之类与存储相关的字段
...oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}h.B += bigger...h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {...h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {...h.extra.nextOverflow = nextOverflow}
这里注意到这段代码: newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)。第一反应是扩容的时候就马上申请并初始化内存了吗?假设涉及大量的内存分配,那挺耗费性能的…
然而并不,内部只会先进行预分配,当使用的时候才会真正的去初始化
第三阶段:扩容
在源码中,发现第三阶段的流转并没有显式展示。这是因为流转由底层去做控制了。但通过分析代码和注释,可得知由第三阶段涉及 growWork 和 evacuate 方法。如下:
func growWork(t *maptype, h *hmap, bucket uintptr) {evacuate(t, h, bucket&h.oldbucketmask())if h.growing() {evacuate(t, h, h.nevacuate)}}
在该方法中,主要是两个 evacuate 函数的调用。他们在调用上又分别有什么区别呢?如下:
- evacuate(t, h, bucket&h.oldbucketmask()): 将 oldbucket 中的元素迁移 rehash 到扩容后的新 bucket
- evacuate(t, h, h.nevacuate): 如果当前正在进行扩容,则再进行多一次迁移
另外,在执行扩容动作的时候,可以发现都是以 bucket/oldbucket 为单位的,而不是传统的 buckets/oldbuckets。再结合代码分析,可得知在 Go map 中扩容是采取增量扩容的方式,并非一步到位
为什么是增量扩容?
如果是全量扩容的话,那问题就来了。假设当前 hmap 的容量比较大,直接全量扩容的话,就会导致扩容要花费大量的时间和内存,导致系统卡顿,最直观的表现就是慢。显然,不能这么做
而增量扩容,就可以解决这个问题。它通过每一次的 map 操作行为去分摊总的一次性动作。因此有了 buckets/oldbuckets 的设计,它是逐步完成的,并且会在扩容完毕后才进行清空
小结
通过前面三个阶段的分析,可以得知扩容的大致过程。我们阶段性总结一下。主要如下:
- 根据需扩容的原因不同(overLoadFactor/tooManyOverflowBuckets),分为两类容量规则方向,为等量扩容(不改变原有大小)或双倍扩容
- 新申请的扩容空间(newbuckets/newoverflow)都是预分配,等真正使用的时候才会初始化
- 扩容完毕后(预分配),不会马上就进行迁移。而是采取增量扩容的方式,当有访问到具体 bukcet 时,才会逐渐的进行迁移(将 oldbucket 迁移到 bucket)
这时候又想到,既然迁移是逐步进行的。那如果在途中又要扩容了,怎么办?
again:bucket := hash & bucketMask(h.B)...if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}
在这里注意到 goto again 语句,结合上下文可得若正在进行扩容,就会不断地进行迁移。待迁移完毕后才会开始进行下一次的扩容动作
迁移
在扩容的完整闭环中,包含着迁移的动作,又称 “搬迁”。因此我们继续深入研究 evacuate 函数。接下来一起打开迁移世界的大门。如下:
type evacDst struct {b *bmapi intk unsafe.Pointerv unsafe.Pointer}
evacDst 是迁移中的基础数据结构,其包含如下字段:
- b: 当前目标桶
- i: 当前目标桶存储的键值对数量
- k: 指向当前 key 的内存地址
- v: 指向当前 value 的内存地址
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))newbit := h.noldbuckets()if !evacuated(b) {var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x.v = add(x.k, bucketCnt*uintptr(t.keysize))if !h.sameSizeGrow() {y := &xy[1]y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.v = add(y.k, bucketCnt*uintptr(t.keysize))}for ; b != nil; b = b.overflow(t) {...}if h.flags&oldIterator == 0 && t.bucket.kind&kindNoPointers == 0 {b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))ptr := add(b, dataOffset)n := uintptr(t.bucketsize) - dataOffsetmemclrHasPointers(ptr, n)}}if oldbucket == h.nevacuate {advanceEvacuationMark(h, t, newbit)}}
- 计算并得到 oldbucket 的 bmap 指针地址
- 计算 hmap 在增长之前的桶数量
- 判断当前的迁移(搬迁)状态,以便流转后续的操作。若没有正在进行迁移
!evacuated(b),则根据扩容的规则的不同,当规则为等量扩容sameSizeGrow时,只使用一个evacDst桶用于分流。而为双倍扩容时,就会使用两个evacDst进行分流操作 - 当分流完毕后,需要迁移的数据都会通过
typedmemmove函数迁移到指定的目标桶上 - 若当前不存在 flags 使用标志、使用 oldbucket 迭代器、bucket 不为指针类型。则取消链接溢出桶、清除键值
- 在最后
advanceEvacuationMark函数中会对迁移进度hmap.nevacuate进行累积计数,并调用bucketEvacuated对旧桶 oldbuckets 进行不断的迁移。直至全部迁移完毕。那么也就表示扩容完毕了,会对hmap.oldbuckets和h.extra.oldoverflow进行清空
总的来讲,就是计算得到所需数据的位置。再根据当前的迁移状态、扩容规则进行数据分流迁移。结束后进行清理,促进 GC 的回收
总结
在本章节我们主要研讨了 Go map 的几个核心动作,分别是:“赋值、扩容、迁移” 。而通过本次的阅读,我们能够更进一步的认识到一些要点,例如:
- 赋值的时候会触发扩容吗?
- 负载因子是什么?过高会带来什么问题?它的变动会对哈希表操作带来什么影响吗?
- 溢出桶越多会带来什么问题?
- 是否要扩容的基准条件是什么?
- 扩容的容量规则是怎么样的?
- 扩容的步骤是怎么样的?涉及到了哪些数据结构?
- 扩容是一次性扩容还是增量扩容?
- 正在扩容的时候又要扩容怎么办?
- 扩容时的迁移分流动作是怎么样的?
- 在扩容动作中,底层汇编承担了什么角色?做了什么事?
- 在 buckets/overflow buckets 中寻找时,是如何 “快速” 定位值的?低八位、高八位的用途?
- 空槽有可能出现在任意位置吗?假设已经没有空槽了,但是又有新值要插入,底层会怎么处理
最后希望你通过本文的阅读,能更清楚地了解到 Go map 是怎么样运作的 :)
