Kafka 与Spark的集成
在本章中,我们将讨论如何将Apache Kafka与Spark Streaming API集成。
关于Spark
Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理。数据可以从诸如Kafka,Flume,Twitter等许多源中提取,并且可以使用复杂的算法来处理,例如地图,缩小,连接和窗口等高级功能。最后,处理的数据可以推送到文件系统,数据库和活动仪表板。弹性分布式数据集(RDD)是Spark的基本数据结构。它是一个不可变的分布式对象集合。RDD中的每个数据集划分为逻辑分区,可以在集群的不同节点上计算。
与Spark集成
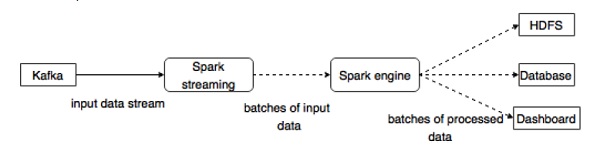
Kafka是Spark流式传输的潜在消息传递和集成平台。Kafka充当实时数据流的中心枢纽,并使用Spark Streaming中的复杂算法进行处理。一旦数据被处理,Spark Streaming可以将结果发布到另一个Kafka主题或存储在HDFS,数据库或仪表板中。下图描述了概念流程。
现在,让我们详细了解Kafka-Spark API。
SparkConf API
它表示Spark应用程序的配置。用于将各种Spark参数设置为键值对。
SparkConf
类有以下方法 -
set(string key,string value) - 设置配置变量。
remove(string key) - 从配置中移除密钥。
setAppName(string name) - 设置应用程序的应用程序名称。
get(string key) - get key
StreamingContext API
这是Spark功能的主要入口点。SparkContext表示到Spark集群的连接,可用于在集群上创建RDD,累加器和广播变量。签名的定义如下所示。
- public StreamingContext(String master, String appName, Duration batchDuration,
- String sparkHome, scala.collection.Seq<String> jars,
- scala.collection.Map<String,String> environment)
主 - 要连接的群集网址(例如mesos:// host:port,spark:// host:port,local [4])。
appName - 作业的名称,以显示在集群Web UI上
batchDuration - 流式数据将被分成批次的时间间隔
- public StreamingContext(SparkConf conf, Duration batchDuration)
通过提供新的SparkContext所需的配置创建StreamingContext。
conf - Spark参数
batchDuration - 流式数据将被分成批次的时间间隔
KafkaUtils API
KafkaUtils API用于将Kafka集群连接到Spark流。此API具有如下定义的显着方法 createStream
。
- public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
- StreamingContext ssc, String zkQuorum, String groupId,
- scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
上面显示的方法用于创建从Kafka Brokers提取消息的输入流。
ssc - StreamingContext对象。
zkQuorum - Zookeeper quorum。
groupId - 此消费者的组ID。
主题 - 返回要消费的主题的地图。
storageLevel - 用于存储接收的对象的存储级别。
KafkaUtils API有另一个方法createDirectStream,用于创建一个输入流,直接从Kafka Brokers拉取消息,而不使用任何接收器。这个流可以保证来自Kafka的每个消息都包含在转换中一次。
示例应用程序在Scala中完成。要编译应用程序,请下载并安装 sbt
,scala构建工具(类似于maven)。主要应用程序代码如下所示。
- import java.util.HashMap
- import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming._
- import org.apache.spark.streaming.kafka._
- object KafkaWordCount {
- def main(args: Array[String]) {
- if (args.length < 4) {
- System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
- System.exit(1)
- }
- val Array(zkQuorum, group, topics, numThreads) = args
- val sparkConf = new SparkConf().setAppName("KafkaWordCount")
- val ssc = new StreamingContext(sparkConf, Seconds(2))
- ssc.checkpoint("checkpoint")
- val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
- val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
- val words = lines.flatMap(_.split(" "))
- val wordCounts = words.map(x => (x, 1L))
- .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
- wordCounts.print()
- ssc.start()
- ssc.awaitTermination()
- }
- }
构建脚本
spark-kafka集成取决于Spark,Spark流和Spark与Kafka的集成jar。创建一个新文件 build.sbt
,并指定应用程序详细信息及其依赖关系。在编译和打包应用程序时, sbt
将下载所需的jar。
- name := "Spark Kafka Project"
- version := "1.0"
- scalaVersion := "2.10.5"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
- libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
- libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
编译/包装
运行以下命令以编译和打包应用程序的jar文件。我们需要将jar文件提交到spark控制台以运行应用程序。
- sbt package
提交到Spark
启动Kafka Producer CLI(在上一章中解释),创建一个名为 my-first-topic
的新主题,并提供一些样本消息,如下所示。
- Another spark test message
运行以下命令将应用程序提交到spark控制台。
- /usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
- -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
- -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
此应用程序的示例输出如下所示。
- spark console messages ..
- (Test,1)
- (spark,1)
- (another,1)
- (message,1)
- spark console message ..
